
My Dissertation
(Page currently under construction)
The implications of socioindexical order for adolescent stylistic development and sound change
In my dissertation, I explore the relationship between socioindexical order and stylistic practice for sound changes in progress. By socioindexical order, I mean the degree to which a variant (in this case, a pronunciation) is socially meaningful. For example, one can say that Southern US English vowel pronunciations are extremely socially meaningful – people have very strong and well-defined ideas about what it says about you, your personality, and even your intelligence if you have a strong Southern accent. Of course, these are harmful, essentialistic assumptions based on stereotypes, but people hold onto them for dear life nonetheless. Contrast Southern US English vowel pronunciations with something like Colorado English vowel pronunciations. You likely don’t have a very well-defined sense of what Colorado English vowels sound like and what differentiates them from the vowels of other American English varieties. The ideas that people hold about what it means to sound Coloradan – what it says about your personality, abilities, or social positioning – are probably also more nebulous. We can say that Colorado English vowels are much less socially meaningful than US Southern English vowels, both on a national level, and likely locally in Colorado, too. And by stylistic practice, I mean the ways that people use language (certain pronunciations) to signal social information about themselves – whether it be group membership or some personality characteristic, like laid-back, cool, or popular. I am interested in looking at the relationship between these two things specifically as it pertains to sound change (where a community changes its pronunciation over time as a group) because stylistic practice is often argued to be key to spreading new pronunciations around a community and cementing them in the community’s speech. And above all, adolescents are thought to be the single most important group in driving this process of pushing a community toward sound change (Eckert, 2011, 2019). This makes sense when you think about how older generations frequently complain about the youths’ newfangled words and ways of speaking. Members of older generations often respond conservatively to adolescents’ role as the movers and shakers of linguistic change.
My research question
At the heart of my dissertation research is the following question:
Are sound changes that are very socially meaningful more likely to be used in adolescent stylistic practice (and therefore more likely to travel along that particular route of community spread) than sound changes that are much less socially meaningful?
If the answer to that question is “yes,” then sociolinguistic theory must account for this – if less meaningful sound changes are not being used stylistically by adolescents, then how are they spreading throughout the community?
What sound changes am I looking at?
I’m examining two sound changes that are currently ongoing in Michigan English: the replacement of the Northern Cities Shift (NCS) vowel system with the Low-Back-Merger-Shift (LBMS) vowel system, and the increasing use of the creaky voice register. I’ll explain what each of these is in turn.
Vowel change: NCS -> LBMS
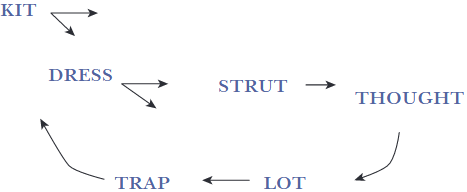
For a long time – probably for close to 100 years – a particular vowel pronunciation system has predominated in Michigan English, and much of what linguists refer to as the “Inland North.” This vowel system is typically referred to as the “Northern Cities Shift,” and it’s been the object of intense linguistic investigation for decades (Labov, Yaeger, & Steiner, 1972). Click here to see a video of the founder of modern sociolinguistics, William Labov, explaining the shift in the 2005 documentary Do You Speak American? Important to my dissertation work are two vowels in the system: the vowel in TRAP, and the vowel in LOT. In the NCS, these two vowels are pronounced quite differently than in other parts of the US. TRAP is pronounced higher up and more forward in the mouth (that is, the tongue is higher up and in a forward position in the mouth when it’s pronounced), and LOT is pronounced more toward the front of the mouth than in most other American English varieties. This is how linguists typically visualize this:
If you’re not already familiar with how linguists talk about and visualize vowel data, then that figure is probably pretty confusing, even with my explanation. It helps to see a diagraph like this:
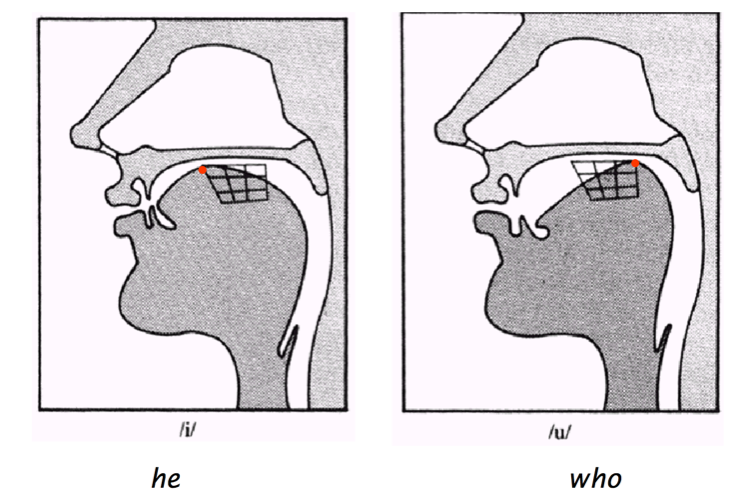
That figure shows the position of the tongue when the vowel /i/ (the vowel in “he”) is pronounced vs. where the tongue is positioned when the vowel /u/ (the vowel in “who”) is pronounced. You can see that the tongue is positioned more forward when /i/ is being produced than for /u/. This shows the front-back distinction. The high-low distinction is just like this, except it moves along the “Y-axis,” so to speak, rather than the “X-axis.”
The NCS is currently on the decline in Michigan – and in many other areas of the Inland North (Acton et al., 2021; Nesbitt, 2018, 2019, 2021, 2023; Sneller & Greeson, 2025; Wagner, Mason, Nesbitt, Pevan, & Savage, 2016). And it’s being replaced by what linguists call the “Low-Back-Merger-Shift.” Crucially, this new pattern is primarily defined by movement in the two aforementioned vowels, TRAP and LOT. TRAP is splitting – the vowel is pronounced lower and backer in the mouth when it’s before a consonant like /p/ or /t/, and it’s still pronounced high and front when it’s before a nasal consonant like /m/ or /n/. In this dissertation I deal primarily with the first kind of TRAP, the one that’s lowering and backing in the LBMS. And LOT in the LBMS is being pronounced more toward the back of the mouth, and also in a raised position, so that it’s merging with the pronunciation of THOUGHT (Nesbitt, 2021). This is how linguists visualize the LBMS:
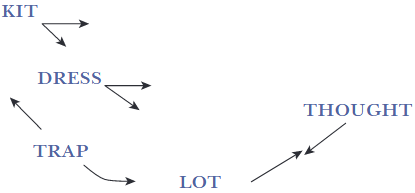
So why am I interested in these two vowels? Well, if you compare the figure for the NCS with the figure for the LBMS, you’ll see that they actually look very similar. The vowels that show serious differentiation between the two are TRAP and LOT. Because I’m interested in how social meaning interacts with the way sound change takes place, I’m looking at TRAP and LOT – because they’re the two vowels that stand to be noticed by speakers, as they sound different depending on if they’re pronounced in the NCS way or the LBMS way. And because they stand to be noticed, they also stand to have social meaning attributed to them. In fact, Michiganders were adamant for a long time that they didn’t have any accent at all (Preston, 1996). What they meant by this was that they thought they spoke “Standard American English.” This was in large part due to the fact that most people in Michigan mainly interacted with other Michiganders that sounded the same as they did. But this perception has started to change, along with the pronunciations themselves. Because the way that TRAP and LOT are being pronounced is changing generationally (younger people sound different than older people), Michiganders are able to hear that they do, in fact, have an accent. And I’m interested in this process – what other kinds of social meaning are Michiganders attributing to this vowel variation? And crucially, are these social meanings allowing the new LBMS pronunciations to be used in stylistic practice?
So I devised an experiment to investigate these potential social meanings. This experiment was a matched-guise test – I recorded a speaker (who could naturally pronounce TRAP and LOT in both an NCS and LBMS way) reading a passage that had several tokens of both vowels in it. I asked her to read it first in an NCS way, and then in an LBMS. Then I had her read it one more time. I took this last recording and duplicated it. I extracted the TRAP/LOT pronunciations from her NCS recording and spliced them into one version. And I took the TRAP/LOT pronunciations from her LBMS recording and spliced them into the other version. After this, I had two versions of her recording that only differed in terms of those specific vowel pronunciations. I then recruited around 100 college-aged native speakers of Michigan English – half of them were played the NCS version, and half were played the LBMS version. All of them were asked various questions about the speaker’s characteristics and what the recording made them think about the person. These questions were answered on a bounded sliding scale, i.e., “How likely do you think it is that this person is from the American West Coast? Choose a value from 1 to 100, where ‘1’ is ‘very unlikely’ and ‘100’ is ‘extremely likely.’”
The characteristics that were probed (which were chosen based on previous open-ended piloting of the testing stimuli) can be separated into two groups based on sociolinguistic theory about social meaning. This theoretical divide corresponds with the distinction between “very socially meaningful” vs. “much less socially meaningful” I mention in my research question:
Are sound changes that are very socially meaningful more likely to be used in adolescent stylistic practice (and therefore more likely to travel along that particular route of community spread) than sound changes that are much less socially meaningful?
Specifically, these characteristics (referred to as lower-order meanings in the literature) are theorized to be more fundamental, less complicated, and less useful in stylistic practice (Eckert, 2008, 2018; Johnstone, 2009; Johnstone et al., 2006; Labov, 1972; Silverstein, 2003; Sneller and Roberts, 2018): Younger/older, accented, Michigander, Midwestern, rural, wealthy, and (from the) West Coast. And these characteristics (referred to as higher-order meanings in the literature) are theorized to be developed on top of lower-order meanings, more complicated, and more useful in stylistic practice: Annoying, educated, feminine, intelligent, spoiled, and (sounds like a) TikTok influencer. Take a look at these figures:
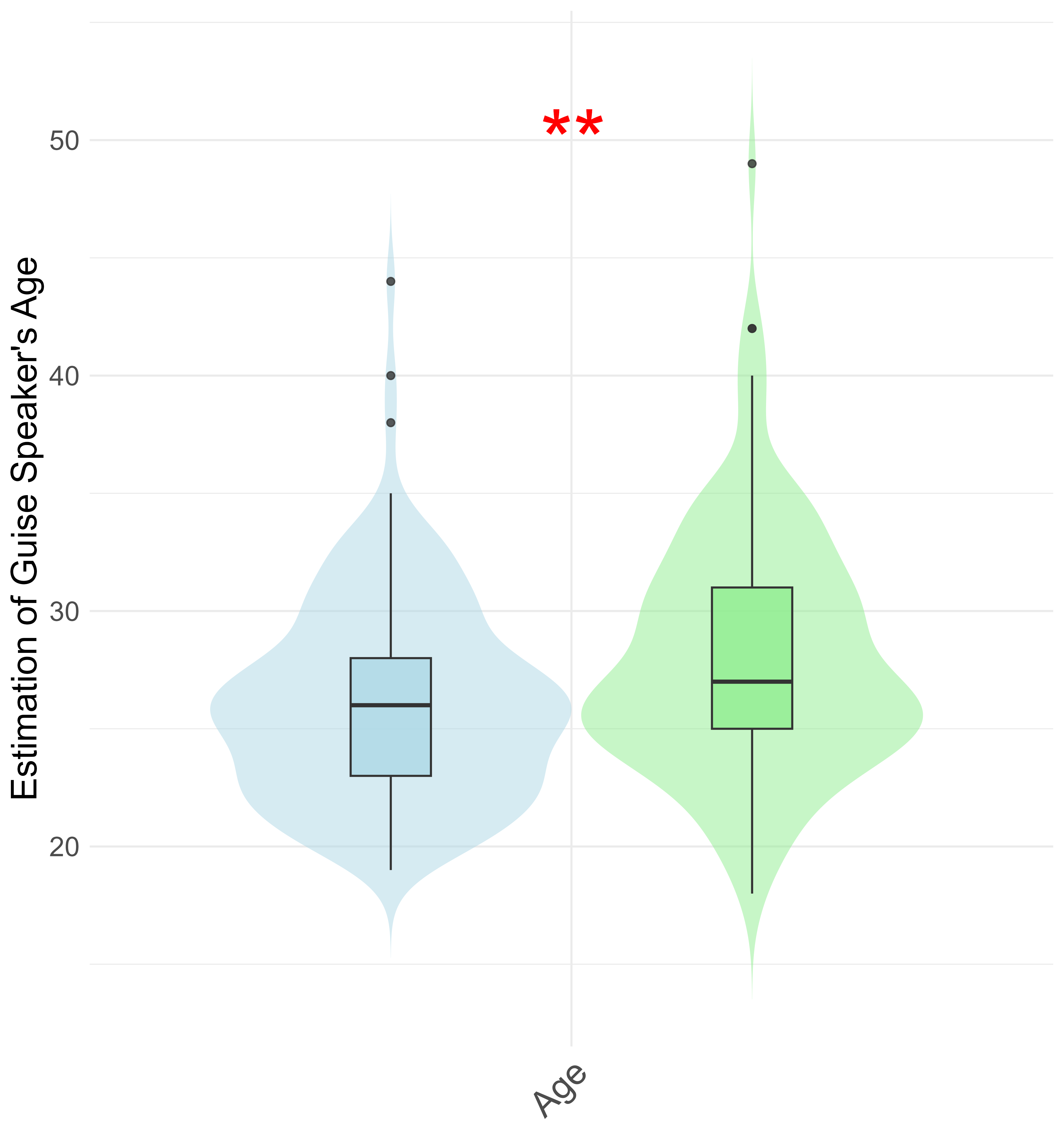
Looking at the distribution of ratings assigned to lower-order meanings, one can see that several categories show a significant difference between the NCS and LBMS recording conditions. These are accent, West Coast, and age. That is, listeners consistently rated the presumed speaker of the NCS guise (recording version) as older and more accented than the presumed speaker of the LBMS guise. The presumed LBMS speaker, on the other hand, was consistently rated as more likely to be from from the American West Coast. Now take a look at this plot:
This plot shows listeners’ ratings of the different higher-order social meanings. None of these differ meaningfully on the basis of guise type. That is, the presumed NCS guise speaker was not rated as significantly different than the presumed LBMS speaker. It appears, therefore, that Michiganders are not assigning complicated social meaning to either variant of this sound change (either the NCS or LBMS). They are assigning lower-order meaning, but not the kind of higher-order meanings that are theorized to be particularly useful when performing the kind of stylistic signaling that I’m interested in. In other words, the use of the NCS or LBMS to signal aspects of one’s identity or social positioning to other people. So if I did find evidence that adolescent speakers are using NCS/LBMS TRAP/LOT to do stylistic work, this would be surprising.
Prosodic change: Modal voice -> creaky voice
The other sound change in progress in Michigan English that I’m examining in my dissertation is the increasing use of creaky voice among younger speakers. Creaky voice is well-known among non-linguists as “vocal fry.” It is a phenomenon that is frequently stereotyped in media discourse at the national and international level and is very often associated with young white women and characteristics essentialistically connected to young white womanhood (Slobe, 2018) – see here, here, here, here, and here. Sociolinguistic research that has formally investigated the social meanings attached to creaky voice has attested a wide range of complicated (higher-order) social meanings: hesitant, nonaggressive, educated, urban-oriented, upwardly mobile, socially distant, and negatively-aligned (Yuasa, 2010; Zimman, 2017; Podesva, 2018). These social meanings are exactly the sort that are theorized to be particularly socially relevant and useful for adolescent speakers looking to linguistically construct and signal their emergent teenager identity. I therefore very much expect to find evidence that creaky voice is being used stylistically.
Although Callier and Podesva (2015) found that increasing use of creaky voice constitute a change in progress in California English (that is, younger people in California are using more creaky voice than older people), no such investigation has been carried out for most North American regional varieties, including Michigan English. Because I am interested in how sound changes are being used stylistically in Michigan English, I first need to determine whether increasing creaky voice use actually is a sound change in progress in Michigan. I sought to answer this question by conducting an apparent time analysis of creaky voice use by 77 speakers in the MI Diaries Corpus. “Apparent time” here means that I take data from speakers at roughly the same time, and then examine their linguistic behavior across the speakers’ birth years. From these patterns, I can make inferences about how language in my sampled community (Michigan) is changing generationally. Apparent time can be contrasted with “real time,” where data from speakers are taken at multiple time points and then examined to establish true chronological patterns.
To conduct this apparent time study, I processed speakers’ (47 women, 30 men) recordings using the REAPER (Robust Epoch And Pitch EstimatoR) software (Talkin, 2015) and antimode method (Dallaston & Docherty, 2019; White, Penney, Gibson, Szakay, & Cox, 2022). This took every 10-millisecond-long chunk of speech and compared it to creaky vs. non-creaky mode and antimode values for each recording, and then assigned that chunk a value of 1 if it fell below the antimode (creaky) and a value of 0 if it didn’t (non-creaky). From this data I was then able to generate mean creakiness values for each speaker. This is what it looks like when I plot these mean values across birthyear:
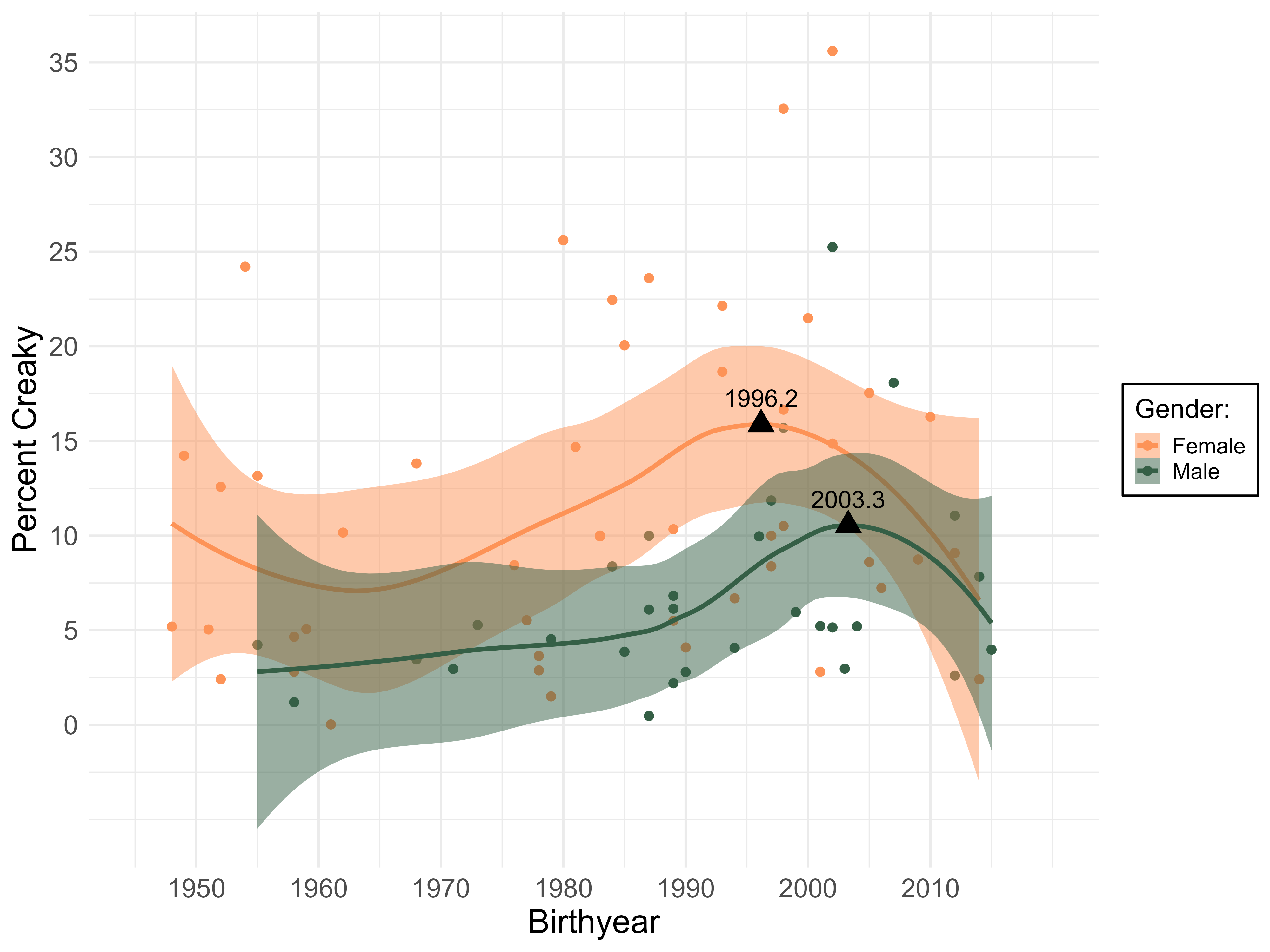
Creakiness is increasing across apparent time for both men and women, and women are leading in this change. This corresponds neatly with Labov’s (2001) foundational assertion that “in the good majority of linguistic changes, women are a full generation ahead of men” (p. 501). The peak year – often referred to in the sociolinguistic literature as the “adolescent peak,” the period where the social drive to adopt a sound change is maximal – for female speakers is also six years before the peak year for male speakers. This may suggest that increasing creakiness in Michigan English is a sound change that’s been going on for some time, and may be nearing completion for female speakers, while male speakers are catching up to them. Because the speaker sample is somewhat imbalanced in terms of gender, however (less male speakers than female speakers), I don’t feel confident in strongly asserting this. One other social distribution pattern is useful to mention and briefly explore here. This pattern emerges when speakers are separated into three groups defined by the population density of their hometowns:
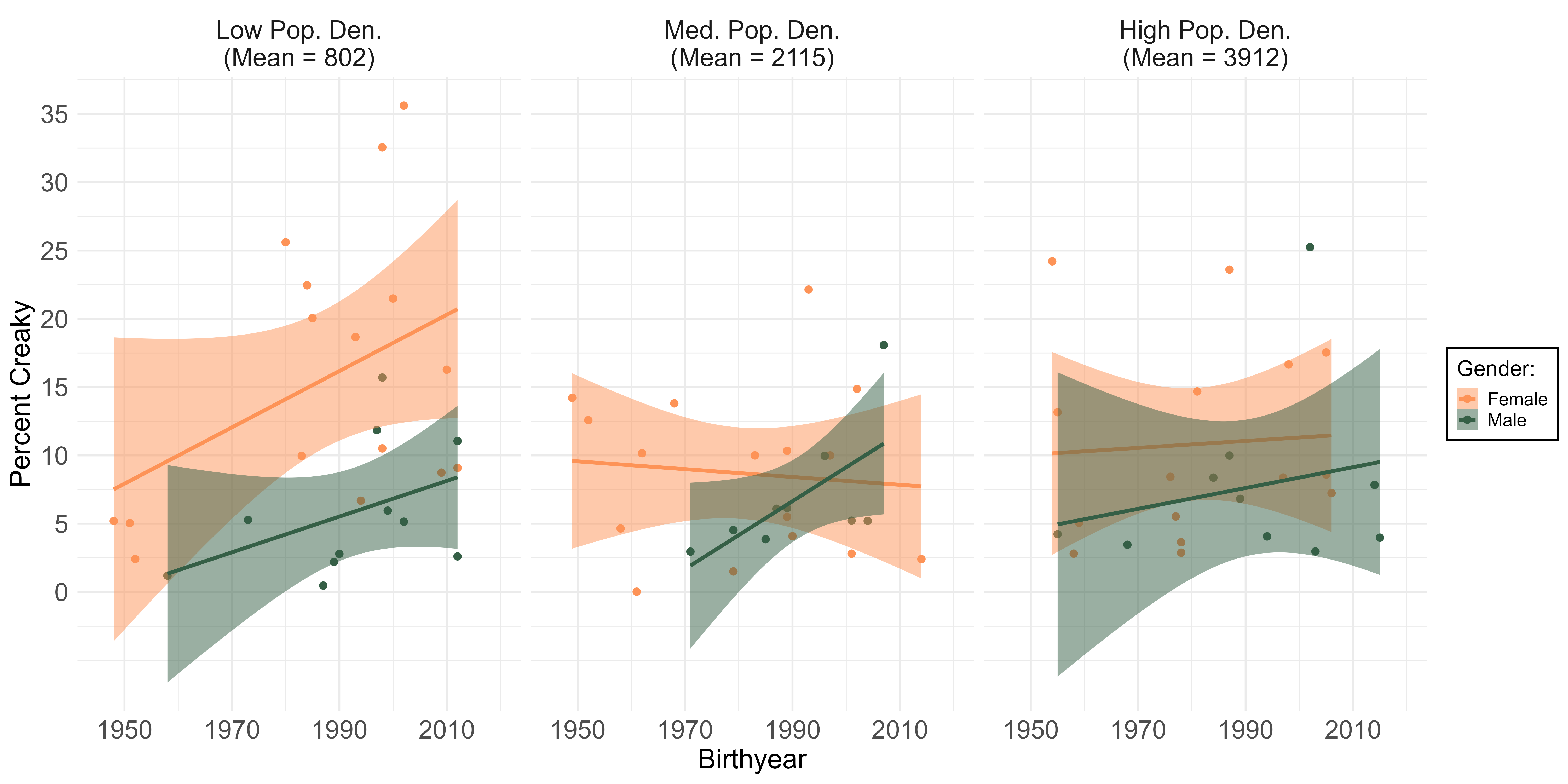
The above figure suggests that this women-led pattern of change is largely driven by speakers from hometowns with lower population density. This is supported by the results of a linear regression model that takes hometown population density, gender, and birthyear as its main predictors, with an interaction between population density and gender. All three main effects were significant: younger female speakers from hometowns with lower population density are creakier than everyone else. The interaction was near-significant (p = .059), tentatively suggesting that this population density effect is weaker for male speakers than it is for female speakers. All of this points to creaky voice potentially being an especially meaningful tool of identity construction for female adolescents in Michigan, especially those who grew up in sparsely populated, white-majority (negative correlation between population density and percentage of population that is white: -0.54) municipalities. These observations inform my dissertation’s main goal of stylistically examining Michigan adolescents’ speech across real time.
How are adolescent speakers in Michigan stylistically using LBMS TRAP/LOT and creaky voice?
I now come to the main investigation of my dissertation: Are adolescent Michiganders using both a very socially meaningful sound change (increasing creaky voice use) as well as a less socially meaningful sound change (LBMS TRAP/LOT) to perform style and express information about their identities? Are they using both sound changes at the same rate and in the same way? And if they are stylistically using creaky voice but not LBMS TRAP/LOT, what does this suggest about our understanding of how sound changes are transmitted throughout a community?
Speakers and data
To perform this stylistic analysis, I examine the real-time linguistic behavior of seven speakers from the MI Diaries Corpus. These speakers, at the time of their start with the project, were between the ages of ten and nineteen. They are all female, which was not a deliberate choice on my part, but reflects a demographic imbalance in the corpus in terms of usable real-time adolescent data – at the time when I planned my dissertation, no male adolescents had been with the project for at least two calendar years. Because of this, I cannot meaningfully and specifically say anything here about the stylistic behavior of male adolescents. Time depth of project participation (how long a participant has been submitting audio recordings to MI Diaries) among the seven female participants varies quite a bit: two speakers have participated for two calendar years, two speakers for three years, one speaker for four years, and two speakers for five years. The data being examined here come from naturalistic “audio diaries” that participants record on their phones and submit to the project through a mobile application. The recordings consist of participants recounting their daily experiences, offering their takes on current events, telling stories from their past, and answering questions that the project send out to them every week. The average recording is around 15 minutes long. For the stylistic analysis, between forty-five minutes and one hour of recordings per year of involvement is used. This usually equates to three or four recordings per speaker, per year.
Stylistic coding methodology
In order to code for style, I adopted a framework originally proposed by Kiesling (2009) and further refined by Holmes-Elliott and Levon (2017). It involves coding sections of speech for individual “speech activities” that both of the above-mentioned studies found were predictive of stylistic variation. I further group these speech activities under four large theoretical groupings: social distance creation (disalignment, hedging, non-mocking quotation, reading out prompts, clarification), face-loss mitigation (questioning, confrontation, confession, gossip, boasting, lamenting), expression of expert information (expert information, expert teaching, personal evaluation), and then all other activities that do not neatly fit into the previous groups.
Overall patterns – creaky voice
In terms of processing data so that participants can be directly compared with one another, the creak data was much more straightforward than the vocalic data. The creak data is already normalized between individual recordings. This is a result of the processing pipeline through which the creak data are derived – each recording had its own individual mode and antimode values against which every 10-millisecond-long chunk was compared and coded as creaky or non-creaky. This inherently normalizes out any potential physiological effects induced by i.e. aging-related changes in the vocal tract.
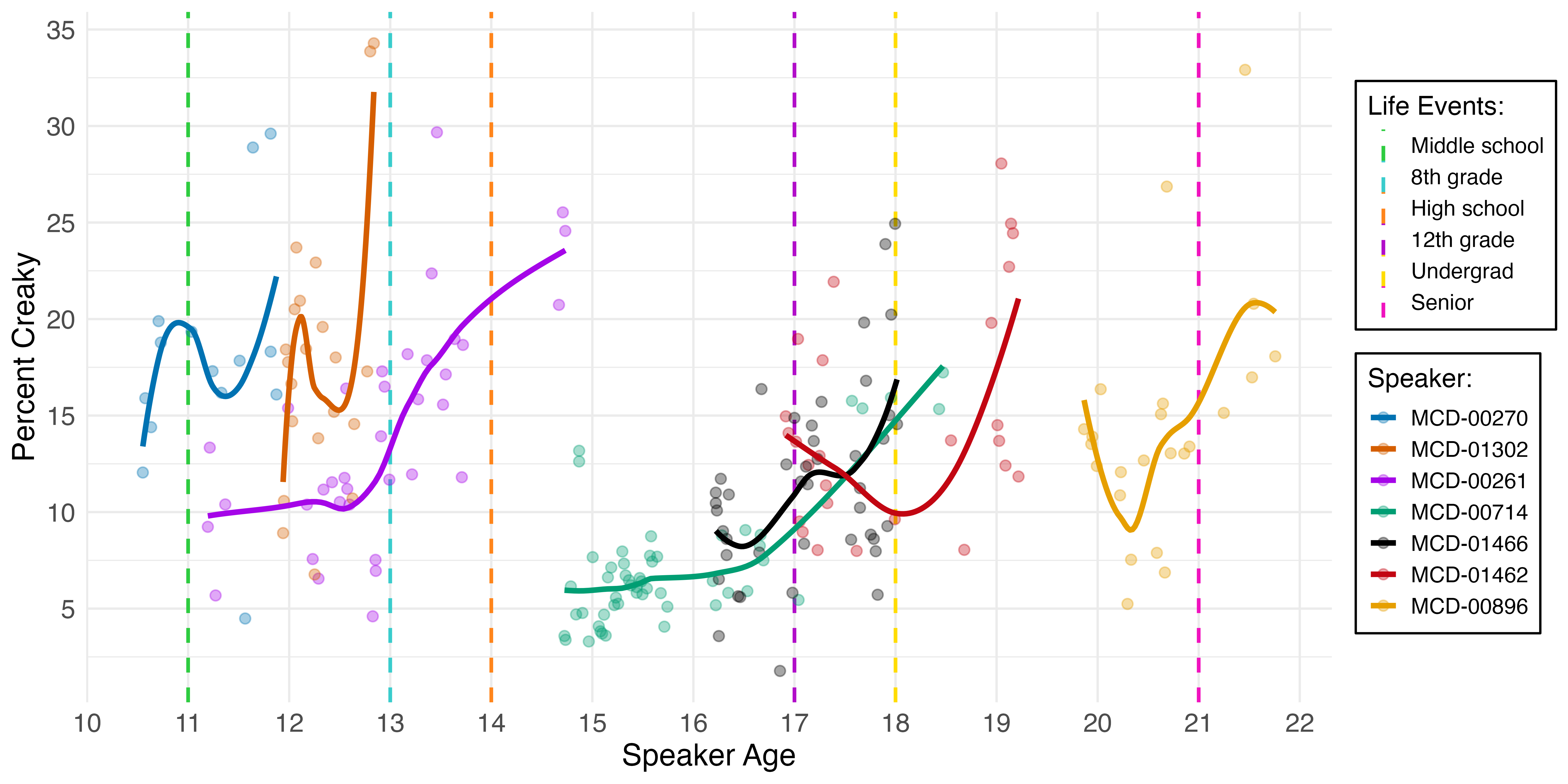
In the above figure, the mean creak values from every recording from the seven participants are laid out with the exact age of participant at time of recording as the X-axis. All of these participants show some degree of creak increase across real time. And several of them show increases that correspond with the overlaid socially important life events, such as entering middle school or starting eighth grade, when increasing use of creak might be driven by a participant’s desire to emphasize their emergent teenager identities or fit in with their peer groups. These key timepoints serve to contextualize the participants’ social lives as I code their data for style.